
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR











AIエンジニアリンググループの中林です。
近年、生成AIを活用した業務効率化や顧客体験の向上が、多くの企業で注目を集めており、それらは多様な業務シナリオに適応できる可能性を秘めています。
しかし、汎用的なモデルをそのまま利用する場合、各企業や業界特有の専門的な要件や、細かな業務ルールに十分対応できないという課題が浮き彫りになってきました。こうした状況を背景に、より高精度で実用的なソリューションを実現するための方法として注目されているのが「ファインチューニング」です。
本記事では、Azure OpenAIにおけるファインチューニングの活用事例を紹介し、このアプローチがもたらす業務効率化やカスタマイズの可能性について解説します。
ファインチューニングとは
まず初めに、私たちの考えるファインチューニングの位置付けについて説明します。
通常、私たちが大規模言語モデル(Large Language Models:以下、LLM)の能力を引き出すためにはプロンプトを利用します。「第45代大統領は誰?」や「次の文を要約して」といった"指示"を与えることで、GPT-4が10兆語と言われる学習データを通じて得た「統計的な知識と文脈理解の仕組み」を基に回答を導き出します。
これに対してファインチューニングは、「特定の業界や事業領域、タスクに特化した精度の高い回答を得るために既存のLLMに対して行う追加学習」と定義されます。自社の規定集や機密情報など、一般公開されていない情報は当然GPTが未学習のため、このデータを追加学習させることで独自性の高いモデルを構築できます。
また、精度の高い回答を得る方法としてRAG(Retrieval-Augmented Generation)もあります。これは、LLMによる回答生成に外部情報の検索を組み合わせることで、最新情報や特定ドメインの知識を加味し、回答精度を向上させる技術です。
それでは、プロンプト、ファインチューニングそしてRAGをどのように使い分ければ効果的でしょうか?
私たちの仮説は、プロンプトで精度が出ない場合にRAG、さらに精度を求めるときはファインチューニングといった直線的な位置付けで捉えるのではなく、それぞれが異なるニーズに応じた役割を持つと考えています。プロンプトでは「複雑な指示内容をどう表現するか」が課題になる場面があります。この場合、ファインチューニングを活用することで、特定のタスクや業務に合わせた指示をより正確に処理できるモデルを構築できます。回答における情報の信頼性を高めることが目的であれば、RAGが効果的です。
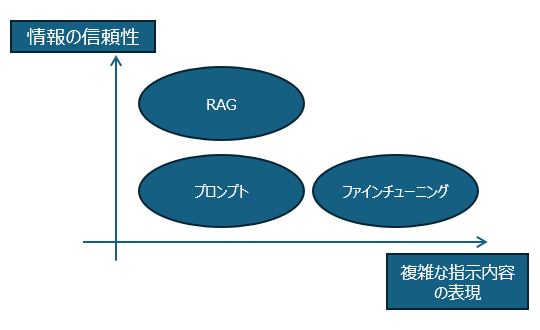
この3つの技術の適用場面は被るところも多々あるので、図としては以下のようになるのかもしれません。
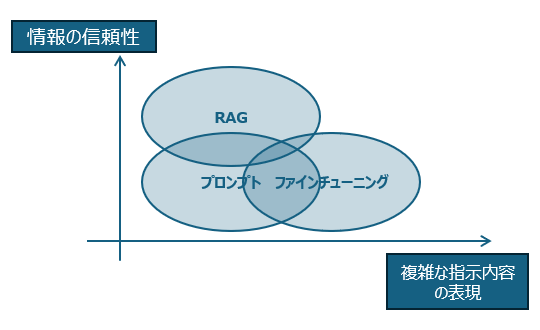
プロンプトとファインチューニングのメリット、デメリットをまとめると概ね以下のようになります。
この中で前出グラフの「複雑な指示内容の表現」に当たる部分である「複雑な条件指示の限界」に焦点を当てて、プロンプトの限界をファインチューニングで補完できるか検証していきます。
LLMによるフローチャート生成の検証
検証を行うにはLLMに複雑な条件を指示して、これを実行してもらう必要があります。私たちは題材としてフローチャートを作成することを選びました。フローチャートの描画には、AT&T研究所が開発したオープンソースの描画ツール「Graphviz」を使用します。
Graphvizは、ノード(処理や判断を表す要素)とそれらを結ぶエッジ(繋がり)を定義したdotファイルを元にフローチャートを描画します。そこでLLMを使った検証の全体像は以下のようになります。

①では以下のようなテキストを使用します。

②のdotファイルの生成について、ファインチューニングしていないモデルでのプロンプト指示と、ファインチューニングしたモデルでの指示のそれぞれを用いて実行し、④で比較検証します。
プロンプトによる試行
システムプロンプトは以下を設定しました。
元のGPT-4o-miniでdotファイルを生成した結果、このようなフローチャートが描画されました。
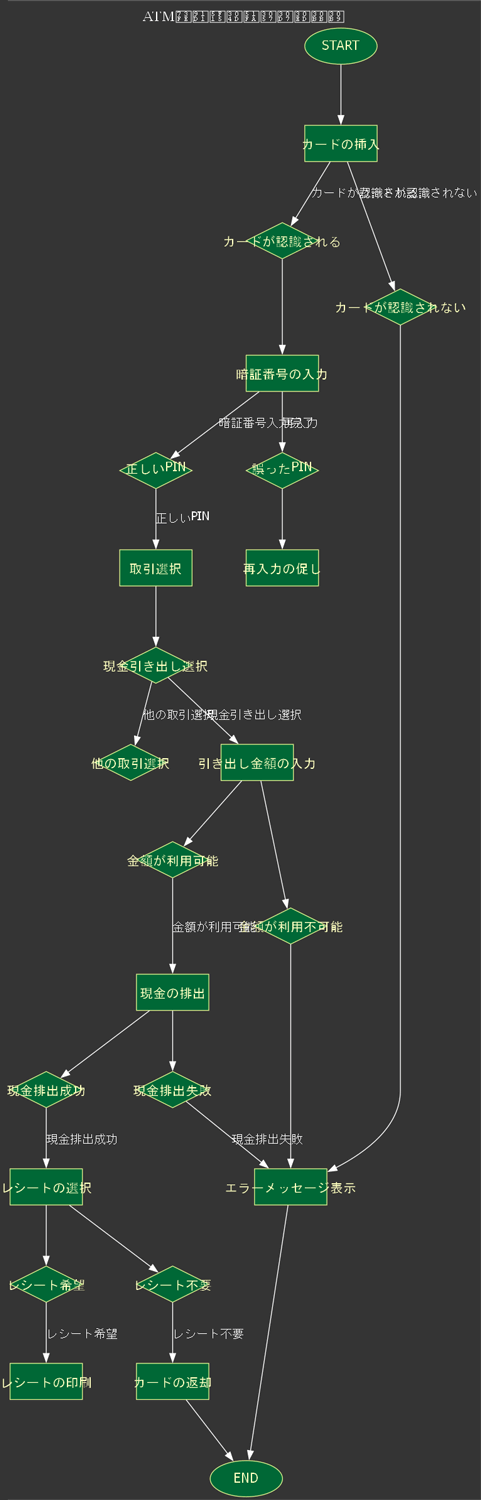
①で与えた処理は11個の処理からできていますが、フローチャートを見るともっと多くの処理が記述されています。また、"判断"を表す菱形のノードがうまく使われておらず、"処理"ノードが判断に使われているなどの不備が散見されます。
ファインチューニングの実施と結果
次に、ファインチューニングの実施例を詳しく見ていきます。
訓練データの準備
以下のようなJSONL形式の訓練データが必要です。今回は50個の訓練データを準備しました。
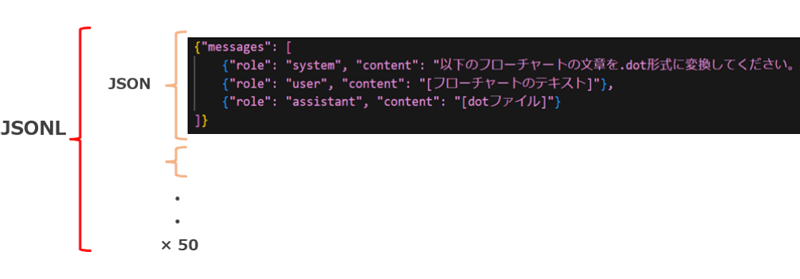
Systemには「フローチャートのテキストを.dot形式に変換してください。ルールは〇〇・・・」といった指示を設定し、User promptには「フローチャートのテキスト」、assistant's outputには「dotファイル」を設定します。フローチャートのテキストはGPTを使用して比較的容易に準備できましたが、dotファイルの正解データは全て手動で作成する必要があり、大変な作業でした。
データアップロードとファインチューニング
それでは、実際にモデルのファインチューニングをしていきます。
Azure OpenAI Studio→「微調整」→「新たなモデルを作成する」を選択します。ベースモデルはGPT-4o-miniを選択します。トレーニングデータとして上記で作成したJSONLをアップロードします。その他パラメータはデフォルトの設定を使用します。
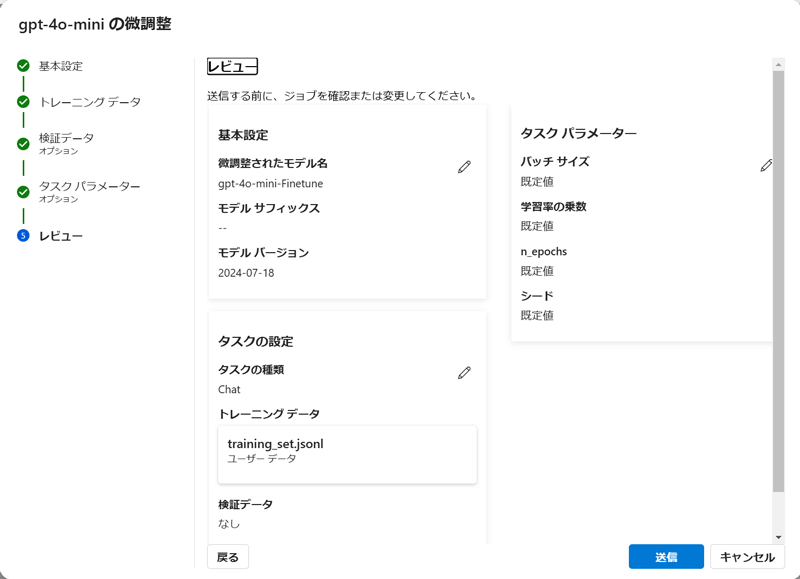
「送信」を押下し、ファインチューニングを実行します。要した時間は1時間ほどでした。モデルはトレーニング完了後にデプロイすることでAPIを呼び出せるようになります。
ファインチューニングモデルでのフローチャート生成
ファインチューニング済のモデルでdotファイルを生成した結果、このようなフローチャートが描画されました。
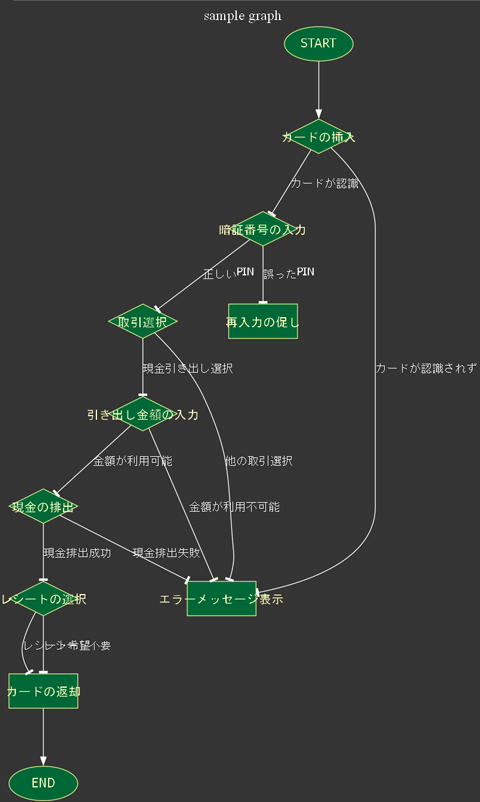
プロンプトのみで描画したフローチャートに比べてファインチューニングで描画したフローチャートは処理の塊やノードの使い方など、一見するとうまくいっているように見えます。次は両者の精度の比較を行なっていきます。
モデルの評価テスト
モデルの性能を客観的に評価するために、以下の評価基準を設定しました。
- フォーマットエラー率:生成されたdotファイルに不要な出力(「以下が生成したdotファイルです」や「----」など)が含まれている割合。
- 構文エラー率:生成されたdotファイルにGraphvizで解析できない構文エラーを含む割合。
- ブロック数の過不足:元のフローチャート文章の項目数と生成された図の項目数を比較し、過不足の程度をスコア1~5で評価。
- フローチャート遷移の正確性:指定された通りに遷移が表現されているかをスコア1~5で評価。
今回のテストでは、24件のケースを使用しました。
※ このテストケース数は検証としては小規模であり、結果の統計的な信頼性には一定の注意が必要です。
評価結果
フォーマットエラー率
ファインチューニングなしのモデルではエラーが発生しませんでしたが、ファインチューニングありのモデルでは1件のフォーマットエラーが発生しました。このフォーマットエラーは、生成されたdotファイルの冒頭および末尾に「-----」という不要な出力が含まれていたことによるものです。
構文エラー率
一方で、Graphvizによる解析に支障をきたすような構文エラーに関しては、ファインチューニングあり・なしの両方のモデルで一切発生しませんでした。
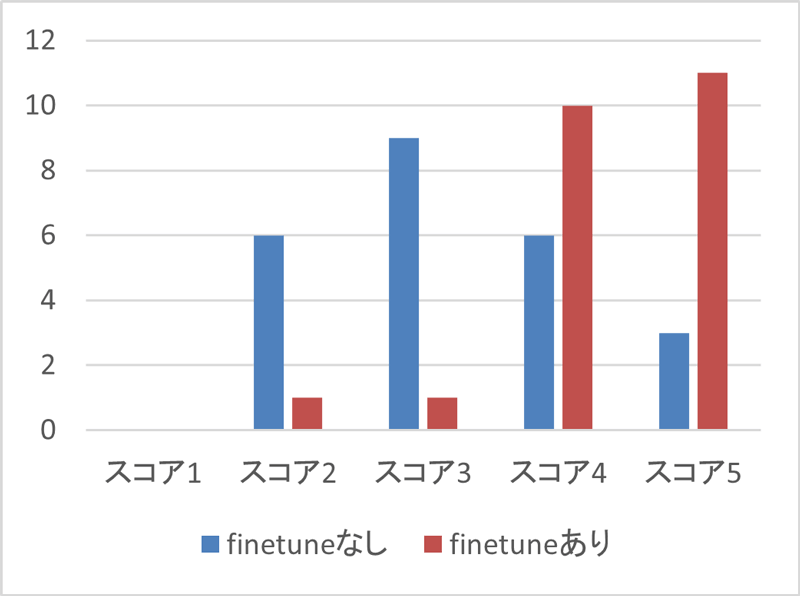
ブロック数の過不足
ブロック数の過不足は、生成されたフローチャートの項目数が元の文章に比べてどの程度一致しているかを評価する指標です。スコアは1(過不足が大きい)から5(過不足なし、フローチャートの分岐図形の使い分け)までの範囲で評価しました。
ファインチューニングなしのモデルでは、スコア1~3のデータが多く、過不足のあるフローチャートが多く見られました。一方、ファインチューニングありのモデルでは、過不足は発生せず、フローチャートの分岐を表す図形の使い分けも多くのケースで見られました。

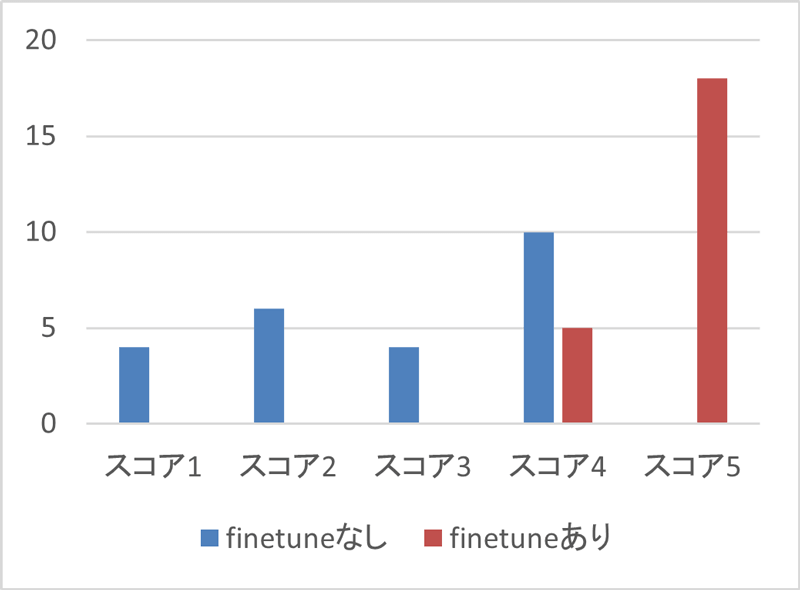
フローチャート遷移の正確性
フローチャートの遷移の正確性は、文章で表現されたフローチャートの流れに対して、正確に遷移が表現されているかを評価する指標です。こちらもスコア1(遷移ミスが多い)から5(正確に遷移できている)で評価しました。
ファインチューニングなしのモデルでは、スコア3以下のデータ数が多く、遷移が正確に表現されていないケースが多く見受けられました。一方で、ファインチューニングありのモデルでは、スコア4や5の割合が顕著に増加しており、遷移の正確性が大幅に向上しました。

フローチャート生成の精度比較
以下は、ファインチューニングなしと、ファインチューニングあり、それぞれのモデルで生成したフローチャートです。
ファインチューニングなしの左は選択肢の度に余計なノードが追加されており、フローチャートとして適しておらず、冗長で見づらいです。ファインチューニングありの右は正確な分岐を表現できており、グラフの見やすさという点で大幅に精度が向上しました。
さいごに
今回取り上げたのはGraphvizに特化したファインチューニングでしたが、他のツールや用途にも同様のアプローチが可能だと考えています。例えば、マークダウン形式のドキュメント生成や特定のデータフォーマットへの変換などです。ファインチューニングによってLLMを特定のタスクやツールに最適化することで、新たな自動化や効率化の可能性が広がります。
私たちは、AI技術を活用したソリューションを提供し、お客様の業務改善をサポートしています。フローチャート自動生成やファインチューニングの活用に興味がありましたら、ぜひお気軽にご相談ください。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR