
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR










Amazon SageMaker Canvasを使った、ノーコードで簡単に作成できる機械学習モデルについて、そのプロセスと成果を前後編の記事で紹介しています。前編では、Amazon SageMaker Canvasの環境構築とデータ可視化をご覧いただきました。
後編では、モデル構築と推定精度の確認、実際にモデルを使った予測について、使用した所感をご紹介します。さらに、Amazon SageMaker Canvasの実践的なユースケースや、使ってみて感じたメリットと課題、最後に今後の展望で締めくくりたいと思います。
Amazon SageMaker Canvasを使用した所感
機械学習モデルの構築からモデルを使った予測までを、以下の通りにまとめます。
- モデルプレビューと特徴量エンジニアリング
- モデル構築と評価
- モデルを使った予測の実践
モデルプレビューと特徴量エンジニアリング
前回「My Models」から作成したモデルを選択し、「Preview model」をクリックすると、モデルプレビューが開始されます。
今回のデータセットでは、5分ほどで以下の通りモデルプレビュー結果が表示されました。プレビュー中の画面上部には、「Validating data」処理を実行するメッセージが表示されます。これは、不適切なモデルタイプが選択されていないか、データの欠損値有無などを確認し、モデルの構築を失敗させる要因がないかのチェックを、Amazon SageMaker Canvas側で実施してくれているようです。こちらのチェック処理は問題なく通過しました。
「Estimated accuracy」の下に、このモデルの予測精度が一目でわかりやすく表示されています。また、その下の「Column impact」は、データセットのカラム毎に、予測への影響度合いを示しています。
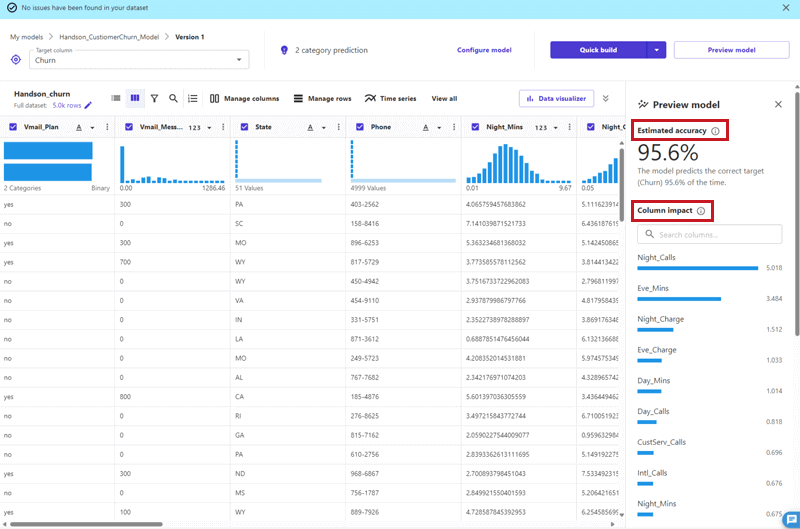
さらにこの画面では、予測精度を向上させるための特徴量エンジニアリングが可能です。カラム名の横のチェックを外すと、モデル構築時に利用する特徴量からノイズを除去できます。他にも中段にある「Manage columns」から「Custom formula」を選択すると、既存のカラムから算出できる値を新しい特徴量として追加することも可能です。
なお、ここで加えた変更は、元のデータセット自体には加わりません。作成したモデル内の定義として扱われるので、チームで共有しているデータセットであっても、変更を加えることを気にする必要はありません。また、以下画面の通り、変更履歴はすべて「Model recipe」に残ります。右端のごみ箱マークをクリックすれば、変更内容ごとに元に戻せます。
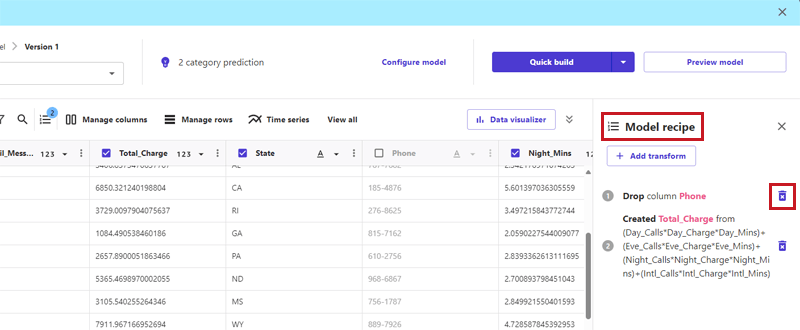
モデル構築と評価
さて、次はモデル構築をしてみます。構築方法としてQuick BuildとStandard Buildが用意されていますが、今回はQuick Buildを選択しました。モデルの利用価値を見定めるような試用であれば、モデル構築の速度重視でこちらを選択するのがおすすめです。実際、5,000行のデータセットが、わずか2分で構築完了しました。
なお、モデル精度を重視する場合や、大規模なデータセット(50,000行以上)を扱う場合、SageMakerの他サービス(Amazon SageMaker Studioなど)とのモデルを共有する場合は、Standard Buildを選択します。Standard Buildは2~4時間かかるとありましたが、セッションログアウトした状態でも続行されるため、ログアウトして課金を止めることが推奨されていました。
続いて、Quick Build後の、モデル評価を見ていきます。Overview、Scoring、Advanced metricsそれぞれ確認します。
Overview
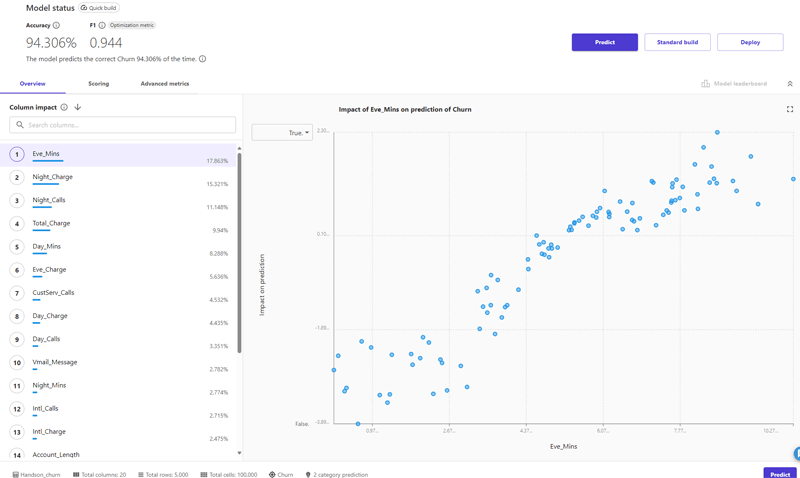
予測精度は94%と、プレビューより少しだけ下がりましたが、高い精度を維持しています。F1スコアも1に近く良好です。ここでは、プレビューでも出てきた「Column impact」について、モデル構築後の情報を確認できます。「Eve_Mins」、「Night_Charge」、「Night_Calls」の順に、予測への影響度合いが高いようです。
グラフ左肩のプルダウンで「True(解約済み)」の予測を選択したグラフを確認すると、以下画面のように正の相関が確認できました。ここから、「True」と予測するにあたり、「Eve_Mins」の値が高いほどその予測に影響を与えると読み取れます。「Night_Charge」、「Night_Calls」のグラフも確認したところ、それぞれ正の相関、負の相関が確認できました。これは予測の時に色々試せそうなので、メモしておきます。
Scoring
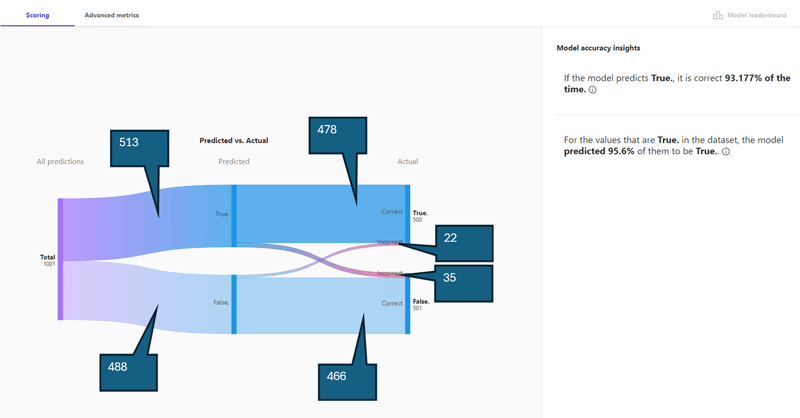
データセット5,000行からテストデータ1,001行を抽出し、モデルで予測した結果と実際の相違を下記に示しました。画面上でカーソルを当てないと各数値が確認できないため、吹き出しで補記しています。例えば、解約した顧客のテストデータは1,001行のうち513行あり、そのうち478行は実際に解約と予測できましたが、残り35行は間違った予測をしたと読み取れます。
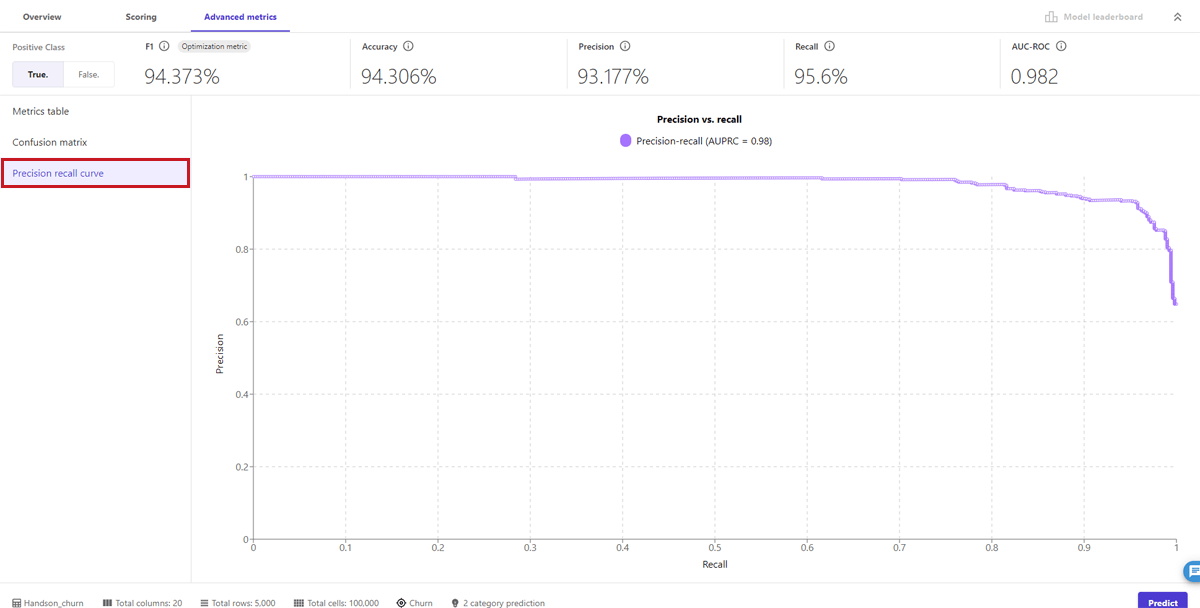
Advanced metrics
「Metrics table」では、中段に表示されているPrecision(適合率)等の算出値が確認できました。「Confusion matrix」は混同行列です。最後に、「Precision recall curve」では、PR曲線が確認できました。グラフの形状から再現率、適合率のバランスが良く、Amazon SageMaker Canvasが構築したモデル性能が高いことが分かります。
モデルを使った予測の実践
ようやくですが、構築したモデルを使って予測を試してみます。先ほどの画面右下にある「Predict」をクリックすると、予測の画面に遷移します。
用意された予測方法は以下の2種類あり、それぞれ試してみました。
| 予測方法 | 説明 |
|---|---|
| Batch Prediction | バッチ予測。一度に大量のデータセットを投入して予測を行う。 例えば、数千行のデータを一度に投入して予測するといった使用。 |
| Single Prediction | シングル予測。個別のデータポイントに対して予測を行う。 例えば、特定のデータを入力して、それに対して予測するといった使用。 |
Batch Prediction
細かい画面遷移は省きますが、既存のデータセットを入力として予測を行う際には、「Manual」か「Automatic」のいずれかを選択します。今回は「Manual」を選択しました。「Automatic」は、元のデータセットが更新される度に、自動でバッチ予測を実行するもののようです。こちらも、いずれ試してみようと思います。
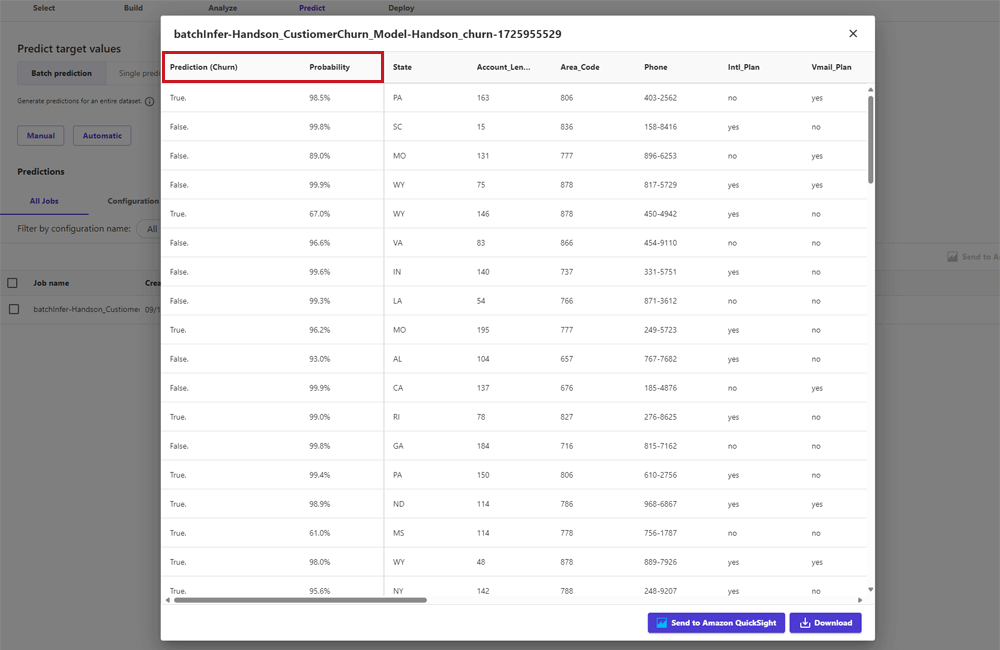
「Manual」でバッチ予測を実行し、プレビューを表示させた画面が以下になります。薄い縦線の右側はデータセットそのもので、左側の「Prediction」「Probability」が新たに追加されています。それぞれ、このデータセットを基に予測した結果と、その予測の信頼度を示しています。この結果は、右下のDownloadからCSV形式ファイルでダウンロードできました。
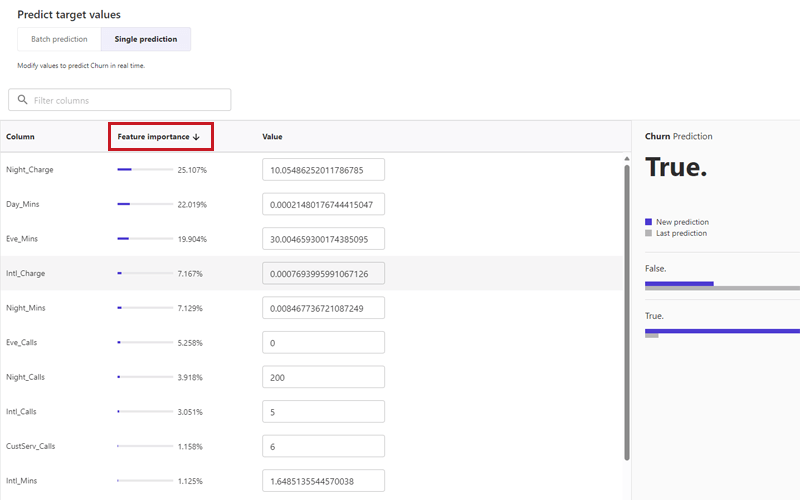
Single Prediction
特徴量をさまざまに変更し、予測結果を即座に確認できるので、こちらの方が色々試せて面白いかもしれません。初期画面では、いずれかのデータがすでに入力されていて、結果は「False(解約していない)」の予測となっていました。ここから特徴量を変更し、予測にどう影響するかを確認してみます。
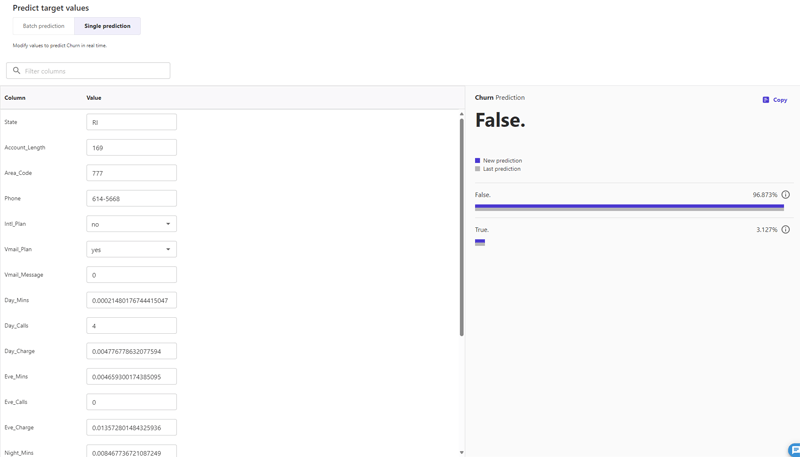
ここで、Quick Build後のOverviewで確認した、Column impactの情報を思い出してみます。「Eve_Mins」と「Night_Charge」が、Trueと予測するのに影響が大きいと示されていました。そこで、元の値に対して「Eve_Mins」に30、「Night_Charge」に10を足して予測がどう変わるかを試してみました。
結果、「Eve_Mins」の変更のみでは結果はFalseのままでしたが、「Night_Charge」の変更も加えると、以下の通り予測結果はTrueに転じました。
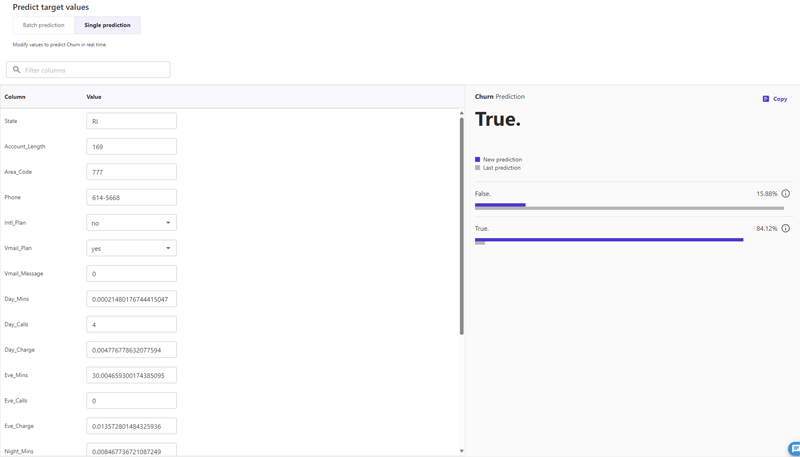
予測の更新は、画面に表示された「Update prediction」もしくは「Update prediction with feature importance」をクリックすると実施されます。前者は新しい入力に対して予測を更新し、後者は更新後に以下の画面で示した「Feature importance」が新たに表示され、どの特徴量が予測結果に影響しているかを確認できます。
また、変更を加えた特徴量は、Value横に表示される時計マークをクリックすると元に戻せます。
Amazon SageMaker Canvasのユースケース
実際の活用事例として、Amazon公式からいくつか紹介されています。気になったものを一部抜粋して、以下に記載します。
- 顧客離れの予測(マーケティング)
企業が顧客の解約を予測し、原因を特定することでターゲットを絞ったキャンペーンを実施。顧客維持に貢献する。 - 住宅価格の予測(不動産)
住宅の位置や部屋の数などのデータを基に、住宅価格を予測するモデルを構築。不動産市場の動向を把握する。 - 需要予測(小売)
過去の販売データを活用し、将来の需要を予測するモデルを構築。在庫管理や仕入れ計画を最適化する。
ふと思い浮かんだのは、製品画像から欠陥品を検出するといったユースケースでした。調べてみたところ、こちらもAmazon SageMaker Canvasを使って試すハンズオン形式でまとめられていましたので、今後試したいと思います。
使用して感じたメリットと課題
簡単にですが、今回Amazon SageMaker Canvasを使って感じたメリットと課題をまとめます。
複雑なカスタムモデル構築や、大規模データセットの処理については試していませんが、これらにどのくらい時間がかかるか、それは課題になるかは気になるところです。また、ハンズオンの冒頭で紹介されているメリットの1つに、Amazon SageMaker Canvasで作成したモデルを、Amazon SageMaker Studioの開発環境と共有できる点が挙げられています。
機械学習の知識はない人でも、具体的なビジネス課題を解決するためにモデルを作成し、そのモデルをデータサイエンス担当がチューニングを行い、改善されたモデルで実践的な予測をしてビジネスに活かすといったサイクルを回せます。
メリット
- ノーコードで簡単に機械学習モデルを構築できる、初心者でも手軽に始められる
- データの可視化と探索を容易とするツールが用意されているので、データ分析が直感的に行える
- 特徴量エンジニアリングで欠損値の検出などが自動化でき、負担が減らせる
- モデルの評価とデプロイが迅速に行えるため、ビジネスのニーズに素早く応えられる
課題
- すべての機能を活用するには、機械学習モデルの評価指標やグラフの見方に関する知識が求められるため、事前学習が必要
今後の展望
今回ハンズオンを通じて、Amazon SageMaker Canvasの機能を一通り使用体験できました。今後は、ハンズオンで紹介されている他ユースケースにも挑戦し、Amazon SageMaker Studioとの連携や、ローコード開発の学習にも取り組んでいきたいと考えています。
前後編をご覧いただいて、機械学習の第一歩としてAmazon SageMaker Canvasに興味を持っていただければ幸いです。ぜひ、自分のデータセットを使って機械学習モデルを作成してみてください。
プロフィール

CCoE部AWS推進チーム
CCoE部AWS推進チームではAWSの各サービスを最大限活用するために日々技術検証や教育プログラムの検討を行っております。その活動のなかで得られた有益な情報を外部へ発信していきます。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR