
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR










機械学習の世界に足を踏み入れたいけれど、プログラミングの知識がなくて躊躇している方も多いのではないでしょうか。Amazon SageMaker Canvasを使えば、ノーコードで簡単に機械学習モデルを作成し、モデルを使った予測や分析が行えます。Pythonのコーディングスキルや、機械学習の深い知識は基本的には必要ありません。
この記事では、AWS公式ハンズオン※を実施した結果をもとに、そのプロセスと成果を前後編で詳しくご紹介します。前編である今回は、環境準備からデータ可視化機能の確認まで、後編では実際のモデル構築と評価のまとめをご覧いただきます。この記事を通じて、機械学習がより身近なものに感じていただけることを願っています。
※ AWS Hands-on for Beginners Amazon SageMaker Canvas 〜 ノーコードで機械学習を始めよう 〜 | AWS Webinar
Amazon SageMaker Canvasとは
Amazon SageMaker Canvasは、クリックやドラッグ&ドロップなどの直感的な操作で、手軽に機械学習の導入と活用ができるツールです。実行環境の構築もわずか数クリックで完了します。
さらに、機械学習モデルの作成に必要なデータセットも、AWS上に蓄積してきたデータに限定されません。手元のCSVファイルをアップロードするだけで、データソースとしてモデル構築に利用できる手軽さは驚きです。もちろん、データソースとしてAmazon S3やAmazon Redshiftなど、他のAWSサービスとの連携もできます。
また、データ準備からモデル構築に至るまで、Amazon SageMaker Canvasがしっかりフォローしてくれます。例えば、準備したデータセットと自分が予測したい内容に対して、適した予測モデルが何かを悩む必要はありません。Amazon SageMaker Canvasが適切なモデルを提案してくれるので、専門知識があまりなくてもスムーズに進められます。
機械学習を活用して、これまで蓄えてきたデータを基に仮説検証サイクルを回してビジネスに活かしたいけれど、機械学習の専門知識も環境もないとお悩みの場合、Amazon SageMaker Canvasを利用することで、スムーズに機械学習の導入から活用に進めます。
環境準備
環境準備として、以下を実施します。
- Amazon SageMakerドメイン作成
- データセット作成
データセット作成のデータソースには、ハンズオンで提供されたCSVファイルを使用しています。CSVファイルは、各顧客の電話回線契約情報や使用状況、現在解約済みかのカラムを含んでいます。また、今回は東京リージョンを使用し、以下の通り実行環境を準備しました。2024年9月現在で、ハンズオンと画面遷移に差分があったので、詳細に記載します。
Amazon SageMakerドメインを作成
まずは、Amazon SageMakerのドメインを作成していきます。
- AWS管理コンソールにてSagemakerを検索し、Amazon SageMakerのサービス画面に移動します。
- 左端のツリーから「Canvas」を選択すると、次の画面に遷移します。
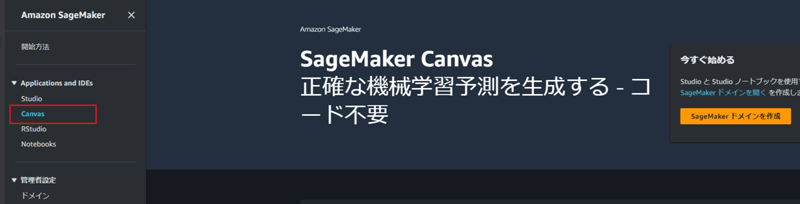
- 画面上の「SageMakerドメインを作成」をクリックします。
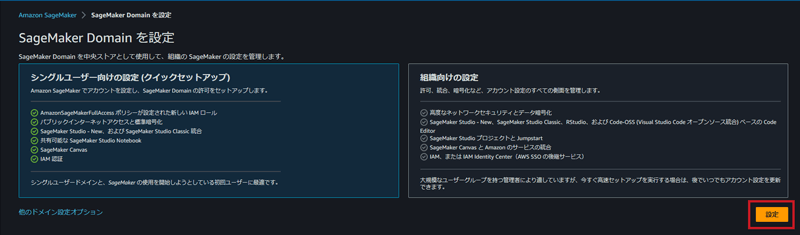
- 以下の画面に遷移し、今回は「クイックセットアップ」を選択の上、右下の「設定」をクリックします。なお、クイックセットアップ内で必要なサービス実行ロールを作成するため、作業ユーザーにロール作成権限がないとエラーとなります。
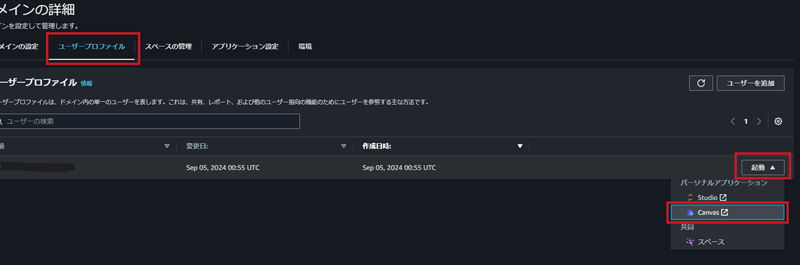
以上で環境の構築が始まります。「ドメインの詳細」の画面で、「ステータス」がReadyに変わればドメイン作成完了です。ドメイン作成後は、Amazon SageMaker Canvasを起動します。
続いて、「ドメインの詳細」画面の中段にある「ユーザープロファイル」タブを選択して作成したドメインを選び、右端の「起動」プルダウンから「Canvas」を選択すると、起動します。
データセット作成
続いて、データセットを作成します。
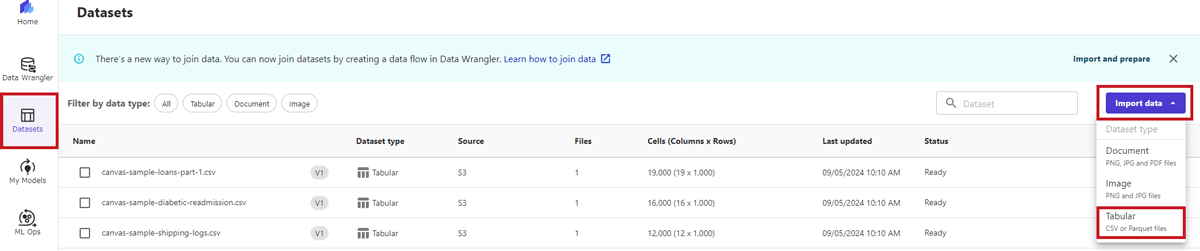
- Amazon SageMaker Canvasの画面で、左端メニュー「Datasets」を選択します。
- 以下の画面通り、右端にある「Import data」プルダウンから「Tabular」を選択します。
- データセットに名前を付けて「Create」をクリックします。(ここでは「Handson_churn」としました)
- 「Select a data source」で「Local upload」が選択された状態で、「Drag a CSV or Parquet file here」へ、データセットに使用するCSVファイルをドラッグ&ドロップします。(ここでローカルファイルアップロード以外にデータソースを選択できます)
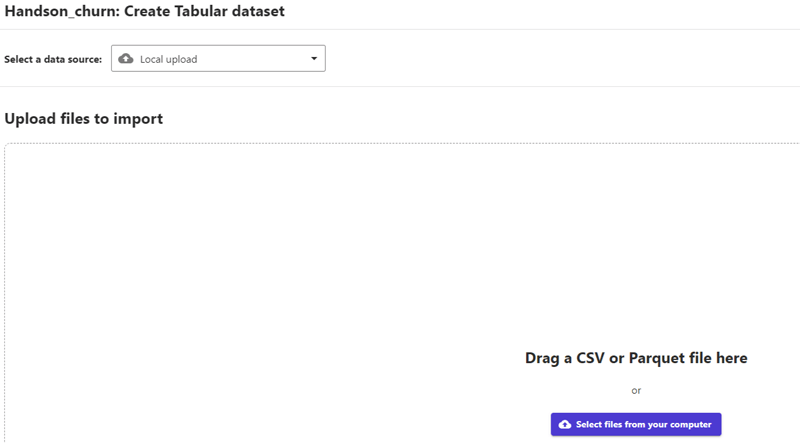
- 右下の「Preview」を選択し、想定した内容でのアップロードが確認できたら「Create dataset」をクリックします。
以上で環境準備は完了です。
使用してみた所感
ここからは詳細な手順を省き、準備したデータセットを使ったAmazon SageMaker Canvasの使い勝手や便利だった機能をまとめます。ハンズオンでは、各顧客の通話状況や解約情報を含むデータソースを用いて、傾向分析や顧客の解約予測をしていきます。
Amazon SageMaker Canvasのデータ可視化機能
簡単にですが、以下の手順を踏むとモデル作成過程のデータ可視化の画面にたどりつきます。
- My Modelsから「Create new model」をクリック
- 「Predictive analysis」を選択し、モデル名を付けてモデルを作成
- 「環境準備」で作成したデータセットを選択し「Select dataset」をクリック
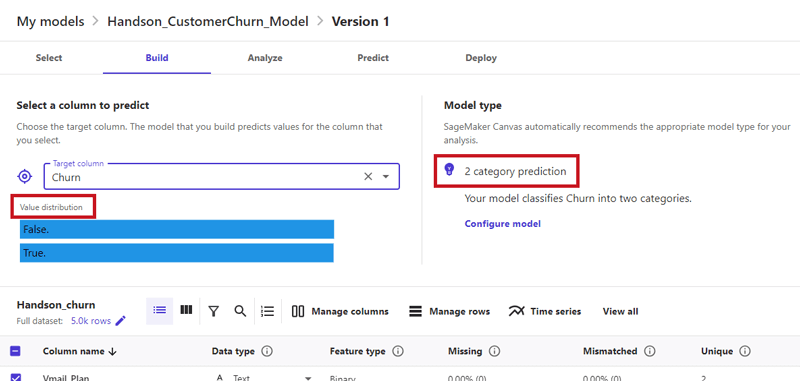
- 今回予測したいカラム「Churn(解約済みか否か)」をTarget columnに選択
ここで注目したいのは、以下の画像右側にある「Model type」欄に表示されているように、Amazon SageMaker Canvasが「2 category prediction(二項分類)」のモデルを提案している点です。これは、今回予測したいカラムが、対象の顧客が解約した(True)、していない(False)という2つの値を持つためで、適切なモデルが提案されています。また、左側の「Value distribution」欄に示されているように、FalseとTrueのサンプル数のバランスも良好です。
Column view
データセットの内容については、以下のような項目が確認できます。
| 項目 | 説明 |
|---|---|
| Column name | データセット内の各列の名前 |
| Data type | 各列のデータ型(例えば、数値、文字列、日付など) |
| Feature type | 機械学習モデルでの使用方法に基づいて、各列の特徴タイプ(例えば、カテゴリカル、数値、テキストなど) |
| Missing | 各列に欠損値がどれだけあるか |
| Mismatched | データ型に一致しない値がどれだけあるか |
| Unique | 各列に含まれるユニークな値の数 |
| Mode | 各列で最も頻繁に出現する値 |
今回アップロードしたCSVファイルは5,000行ありますが、以下の画面で欠損値があるかどうかを簡単に俯瞰できます。
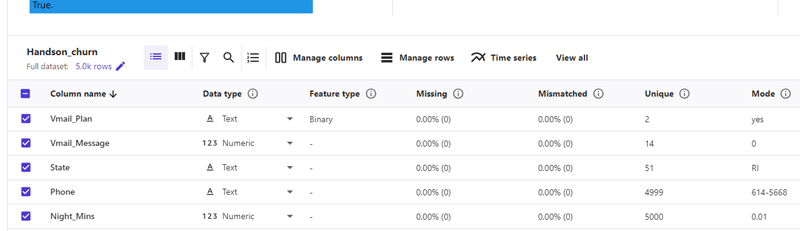
Data visualizer
「Column view」の右上にある「Data visualuzer」をクリックして、データの傾向分析に進めます。
傾向分析に準備されたグラフは、3種用意されています。
| 項目 | 説明 |
|---|---|
| Scatter plot | 散布図。2つの変数の関係を視覚化。 |
| Bar chart | 棒グラフ。データ分布の可視化、グループ化や積上げ表示も可能。 |
| Box plot | 箱ひげ図。データ分布や、外れ値を可視化。 |
今回使ってみて便利だと感じたのは、「Columns」欄から各カラムの右側にある「Drop column here」のエリアにドラッグ&ドロップするだけで、簡単にグラフが描画される点です。比較したいカラムを容易に変更できるため、さまざまな視点からデータを検証するのに最適です。
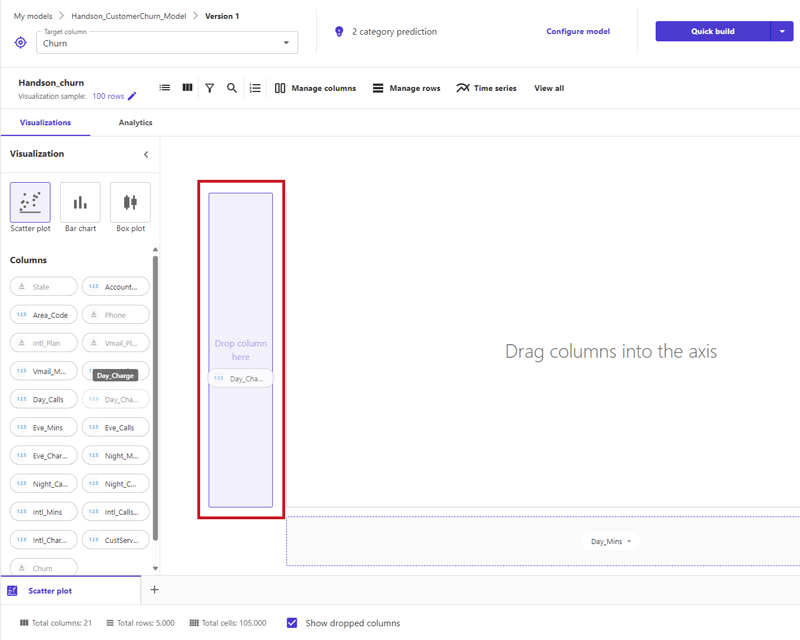
試しに以下のカラムを設定し、解約したかを色分けに選択して描画してみました。
- Eve_Charge(夕方の通話料金)
- Night_Charge(夜間の通話料金)
今回使用したサンプルデータでは、選択した二値に若干の正の相関が確認できました。例えば、「夕方と夜間の通話料金が高い顧客は解約しやすい」、という傾向がみられます。こうしたデータからの気づきは、ビジネスの意思決定や戦略の見直しに役立ちそうです。
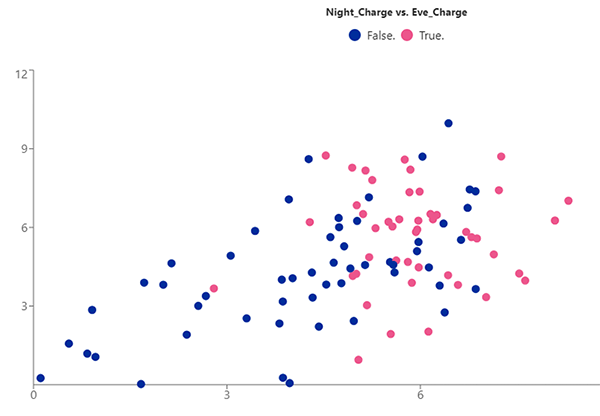
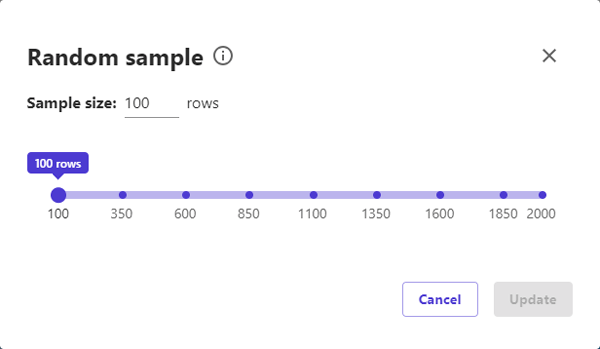
最後に1点補足ですが、描画されている情報はランダムに抽出された、100行のサンプルデータに基づいています。ただし、モデル名の直下にある鉛筆マークから、以下の通りサンプル抽出数を変更できました。サンプル数を増やすことで、より仮説の確からしさが確認できるかもしれません。
さいごに
前編では、Amazon SageMaker Canvasの実行環境準備とデータ可視化について、ハンズオンのプロセスと成果をまとめました。まだ機械学習モデルを使った予測には至っていませんが、まずはAmazon SageMaker Canvasの導入のしやすさを感じてもらい、少しでも興味を持っていただけると嬉しいです。
後半では、準備したデータセットから作成したモデルの推定精度の確認と、モデルのチューニング、評価の実践についてご紹介します。併せて、Amazon SageMaker Canvasの利用ユースケースについても取り上げる予定です。ぜひお楽しみに!
なお、Amazon SageMaker Canvasは1時間ごとに1.9USDのセッション料金がかかりますが、2カ月間は月160時間分の無料利用枠があります。ただし、セッションのログアウトを忘れると予想外の請求が発生しかねないので、作業後はAmazon SageMaker CanvasのUI画面左下から必ずログアウトすることを習慣にしましょう。
プロフィール

CCoE部AWS推進チーム
CCoE部AWS推進チームではAWSの各サービスを最大限活用するために日々技術検証や教育プログラムの検討を行っております。その活動のなかで得られた有益な情報を外部へ発信していきます。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR