
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- OWASP
- SASE
- Tech Crawling
- XDR











最近、社内でGoogle Cloudの検証環境が使えるようになりました。ちょうど何か試してみたいと思っていたところだったので、Natural Language APIの感情分析について検証してみました。
感情分析という言葉に興味を持ったものの、最初は何ができるのかよく分かっていませんでしたが、公式のドキュメントなどを参考に環境構築から分析まで一通り試してみたので、この記事でご紹介します。
Natural Language APIとは
Natural Language APIは、Google Cloudが提供する自然言語処理サービスで、機械学習を使用したテキスト抽出、分析、保存ができます。今回の検証では感情分析のみを対象としましたが、他にもエンティティ分析、エンティティ感情分析、コンテンツ分類、構文解析などの機能が利用できます。各機能の要約は以下の通りです。
| 感情分析 | テキストの執筆者の考え方がポジティブか、ネガティブか、ニュートラルかを判断する |
|---|---|
| エンティティ分析 | テキストに既知のエンティティ(著名人、ランドマークなどの固有名詞)が含まれていないかどうかを調べて、それらのエンティティに関する情報を返す |
| エンティティ感情分析 | エンティティ分析と感情分析を組み合わせ、テキスト内でエンティティについて表現された感情の特定(ポジティブかネガティブか)を試みる |
| コンテンツ分類 | ドキュメント内で見つかったテキストに当てはまる、事前定義されたコンテンツカテゴリのリストを返す |
| 構文解析 | トークンと文の抽出、品詞の特定、各文の係り受け解析ツリーの作成など、テキストの構造を分析する |
検証内容の検討
本検証では、生成AIでダミーのアンケートデータを作成し、それに対して感情分析を行いました。当初は、感情分析という言葉から、短歌や小説の一端のような情緒的な文章を機械がどう読み解くのか興味がありましたが、公式ドキュメントやWebで公開されている他の方の検証結果などを読み、サンプルを使用して挙動確認をしているうちに、そこまで複雑な分析はできないことがわかりました。
あくまでポジティブ、ネガティブ、ニュートラルの3分類が主な分析軸となっており、自由記述のアンケート分析のような、感情の方向性をざっくり把握したいケースでの利用が想定されているようです。製品レビューの分析などにも使えそうだとは感じましたが、手元にちょうど良いデータがなかったため生成AIでダミーアンケートデータを作成し、それを使って分析を実施しました。
Natural Language APIの使い方
Natural Language APIを利用するにあたり、本検証では、公式ガイド※に従って、環境を構築しました。
※ クイックスタート: Natural Language API の設定 | Google Cloud
なお、Natural Language APIのクライアントライブラリはGoやJava、PythonやRubyなど複数の言語で用意されていますが、今回はPythonを選択しました。こちらに関しては、使い慣れた言語のものを選べばよいと思います。
コードを実行するまでの簡単な流れ
① Google Cloudのアカウント、プロジェクト作成
コールされたAPIが実行される環境を準備します。今回は、社内検証環境の既存のアカウントとプロジェクトを使用しました。
② ローカルのAPI実行環境構築
API呼び出しのコードを実行するために必要なツール等を準備します。今回はWindows PCのローカル環境に以下をインストールし、設定しました。
- Google Cloud SDK
- Python実行環境
- Python用のNatural Language API クライアント ライブラリ
③ 認証設定
通常、プログラムからAPIを呼び出す際はGoogle Cloudの認証が必要ですが、事前にGoogleアカウントを使って認証処理を行っておくと、都度認証なしでプログラムからAPIを呼び出せます。以下、簡単ですがその手順となります。
- 1.Google Cloud SDK上で以下コマンドを実行する
gcloud auth application-default login
- 2.ブラウザが起動され、Google Cloudへのログインが求められるので、ログインするアカウントを選択(クリック)する
- 3.パスワードや2段階認証など、通常のブラウザログイン時と同様に入力して画面を進める
- 4.「Google Auth Library にログイン」画面が表示されるので、「次へ」をクリックする
- 5.「Google Auth Library がGoogleアカウントへのアクセスをリクエストしています」画面が表示されるので、「許可」をクリックする
- 6.「gcloud CLIの認証が完了しました」画面が表示される
これでブラウザ上の操作は完了となり、これ以降Google Cloud SDK上で今回ご紹介するコードを実行する際に、上記の認証情報で認証が自動的に行われるようになります。
④ サンプルコードを実行
ここまでで設定が完了したので、実際にチュートリアル※のサンプルコードを実行してみました。ただ、サンプルコードの分析対象テキストが短かったため、少し長めの文章にしています。
※ クイックスタート: クライアント ライブラリを使用して感情分析を行う | Cloud Natural Language API | Google Cloud
- サンプルコード
# 今回必要なライブラリをインポートする from google.cloud import language_v1 # 「LanguageServiceClient」クラスを、クライアントとしてインスタンス化する client = language_v1.LanguageServiceClient() # 分析対象の英語の文章を、「language_v」ライブラリが提供する形式のオブジェクトにセットする text = "This PC is expensive and heavy. However, the performance is high and I like the design." document = language_v1.types.Document( content=text, type_=language_v1.types.Document.Type.PLAIN_TEXT ) # 「analyze_sentiment」メソッドを呼び出して分析を行い、結果を変数にセットする sentiment = client.analyze_sentiment( request={"document": document} ).document_sentiment # 分析対象のテキストと分析結果を表示する print(f"Text: {text}") print(f"Sentiment: {sentiment.score}, {sentiment.magnitude}")

無事に実行できました!結果を見る前に、分析結果の値について簡単に説明します。感情分析で得られる情報としてscoreとmagnitudeがあり、それぞれ以下の通りです。
| score | 感情の方向性を示す正規化された値で、−1.0(強いネガティブ)から+1.0(強いポジティブ)までの範囲でスコアが付与される。文章がポジティブかネガティブかをひと目で把握するには、この値が一番わかりやすい。 |
|---|---|
| magnitude | 感情の強さを表す指標で、scoreとは異なり正規化されていない。テキスト内に感情(ポジティブとネガティブの両方)が含まれるたびに値が加算されていくため、どれくらい感情がこもっているかを数値で捉えられる。 |
実行結果では「Sentiment: 0.0, 1.399999976158142」と表示されていますが、1つ目がscore、2つ目がmagnitudeを表しています。なので、「This PC is expensive and heavy. However, the performance is high and I like the design.(このPCは高価かつ重い。ただ性能は高く、デザインは気に入っている。)」という文章に対してscoreは0.0となり、ポジティブな内容とネガティブな内容が同じ程度入った文章なので想定通りです。Magnitudeは1.399999976158142で、多少感情の入った内容だったので0ではないという結果でした。同じような内容で文章量を増やせば、この値も増えると思われます。
データを準備し、コードを書いて実行
無事にサンプルコードが実行できたので、続いてアンケートデータの分析を試してみました。
冒頭でも触れましたが、実際のアンケートデータを用意するのは難しかったので、今回は生成AIでダミーのアンケートデータを作っています。検証したいことは、自由記述形式で書かれた文章のポジティブ・ネガティブの感情分析と評価なので、データ構造はシンプルに1件あたり1行で、アンケートデータの項目も自由記述の文章1つのみとしました。なお、アンケートのテーマは「自社新商品のシャンプーを使用したユーザの感想」を想定しました。
作成したデータは以下のような形で、今回は48件のデータ(文章)を用意しました。こちらは、データ作成時に特に指定をしませんでしたが、ポジティブな意見とネガティブな意見の割合は以下の通りでした。
| ポジティブな意見 | 35件(約73%) |
|---|---|
| ネガティブな意見 | 6件(約13%) |
| ポジティブとネガティブを含む意見 | 7件(約14%) |
| ニュートラルな意見 | 0件(0%) |
| ポジティブな意見 | 35件(約73%) |
|---|---|
| ネガティブな意見 | 6件(約13%) |
| ポジティブとネガティブを含む意見 | 7件(約14%) |
| ニュートラルな意見 | 0件(0%) |
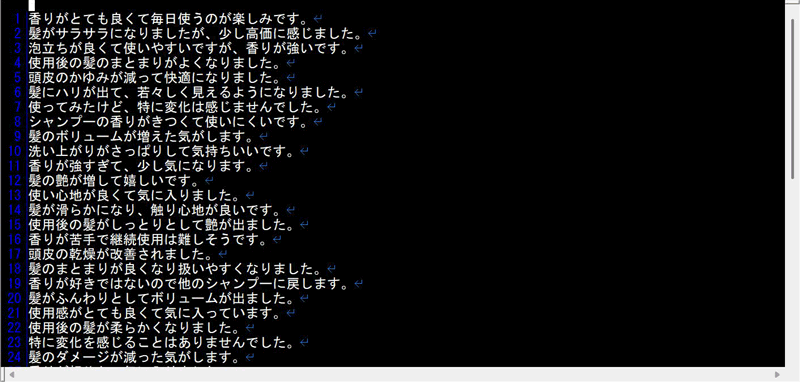
それでは実際にコードを書いて実行してみます。なお、用意したアンケートデータはテキストファイルとしてCloud Storageのバケット上に保存し、コードからそのファイルを取得して解析しています。
- アンケートデータを分析するコード
# 今回必要なライブラリをインポートする from google.cloud import language_v2 # アンケートデータを分析して結果を表示する関数を定義する def sample_analyze_sentiment( # 用意したアンケートデータファイルを格納したバケットのURLの情報をセットする # ★ 【データファイルを格納したバケット名】および【データファイルのパス】は、各自の環境に合わせて入力してください gcs_content_uri: str = "gs://【データファイルを格納したバケット名】/【データファイルのパス】", ) -> None: # 「LanguageServiceClient」クラスを、クライアントとしてインスタンス化する client = language_v2.LanguageServiceClient() # ドキュメントタイプとして、プレーンテキスト形式を設定する document_type_in_plain_text = language_v2.Document.Type.PLAIN_TEXT # 使用言語を設定する language_code = "ja" # バケット上のテキストファイルの内容を読み込んで、Documentクラスをインスタンス化する document = { "gcs_content_uri": gcs_content_uri, "type_": document_type_in_plain_text, "language_code": language_code, } # エンコードタイプの設定をする encoding_type = language_v2.EncodingType.UTF8 # 感情分析を行うメソッドを呼び出して、実行結果を保管する response = client.analyze_sentiment( request={"document": document, "encoding_type": encoding_type} ) # 感情分析結果のうち、アンケートの文章全体としての分析結果を表示する print("【文章全体の評価】") print(f"Document sentiment score: {response.document_sentiment.score}") print(f"Document sentiment magnitude: {response.document_sentiment.magnitude}") print("") # 今回使用した言語を表示する print("【文章の言語】") print(f"Language of the text: {response.language_code}") print("") # 感情分析結果のうち、アンケートデータ1行ごとの分析結果を順次表示する # 「[sentiment score],[sentiment magnitude],[文章]」のフォーマットで、1文章あたり1行の出力とする print("【個別文章ごとの評価】") print("sentiment score,sentiment magnitude,text") for sentence in response.sentences: print(sentence.text.content, sentence.sentiment.score, sentence.sentiment.magnitude, sep=',') # 定義した関数を呼び出す sample_analyze_sentiment()
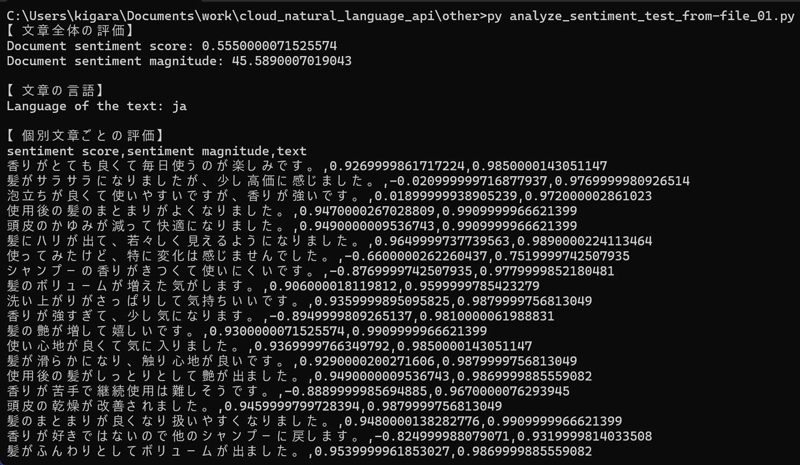
無事、実行できました!まずはアンケートデータ全体としての評価を見てみます。

ここではscoreの数値から全体的にはわりと好印象であることが分かります。また、magnitudeの数値がかなり大きいので大量のデータから分析したこと、およびその中に感情的なフレーズが多く含まれているということが読み取れます。
続いて、個別のデータについても少しだけ見てみます。
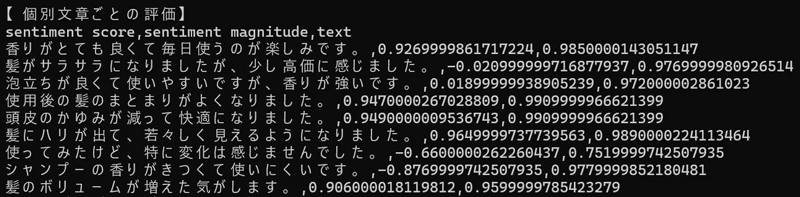
scoreについてはおおむね文章から感じる印象に近い数値のように感じました。ポジティブな意見には0以上、ネガティブな意見には0以下のスコアが付与されています。magnitudeについて、いずれも1付近の値となっています。今回は1文のみのシンプルなテキストだったため、感情の振れ幅にも限界があるのだろうと思います。
上記の通り、scoreの数値については事前に想定していたような結果になりました。ここまででだいぶ長くなってしまいましたが、最後に比較検証として、アンケートデータの「ポジティブ意見」「ネガティブ意見」の割合や文章量を変えて同じ分析を行い、全体としての分析結果がどう変わるのかを見てみます。
追加検証その1:ネガティブ意見多めのデータを分析
今度は、ネガティブな意見を多めにしてみました。それぞれの件数は以下の通りです。
| ポジティブな意見 | 8件(約17%) |
|---|---|
| ネガティブな意見 | 40件(約83%) |
| ポジティブとネガティブを含む意見 | 0件(0%) |
| ニュートラルな意見 | 0件(0%) |
| ポジティブな意見 | 8件(約17%) |
|---|---|
| ネガティブな意見 | 40件(約83%) |
| ポジティブとネガティブを含む意見 | 0件(0%) |
| ニュートラルな意見 | 0件(0%) |
また、ここでは文章量はさきほどと同程度としています。これで分析してみたので、さっそく結果を見ていきます(コード、用意したデータについては割愛します)。

今度はscoreの値が−0.48と、かなりネガティブ寄りな評価となりました。ネガティブな意見を多めに用意したので、想定通りの結果ですね。また、magnitudeについては文章の全体量が変わらず、どの意見にもポジティブもしくはネガティブな意見が入っているため、先ほどとほとんど変わっていません。こちらも、およそ想定していた通りです。
追加検証その2:ポジティブ意見とネガティブ意見を同等、文章量を多めのデータを分析
今度は、ポジティブな意見とネガティブな意見を同じ件数にしてみました。
| ポジティブな意見 | 24件(50%) |
|---|---|
| ネガティブな意見 | 24件(50%) |
| ポジティブとネガティブを含む意見 | 0件(0%) |
| ニュートラルな意見 | 0件(0%) |
| ポジティブな意見 | 24件(50%) |
|---|---|
| ネガティブな意見 | 24件(50%) |
| ポジティブとネガティブを含む意見 | 0件(0%) |
| ニュートラルな意見 | 0件(0%) |
また、ここでは文章量はどのアンケートデータもさきほどの2倍程度としています。これで分析してみたので、結果を見ていきます(コード、用意したデータについては割愛します)。

ポジティブな意見とネガティブな意見を半々で用意したので、scoreの値は0.025とかなり0に近づいています。想定通りの結果ですね。また、magnitudeについては文章の全体量を2倍にし、どの意見にもポジティブもしくは、ネガティブな意見が入っているため先ほどと比べてほぼ2倍の87となっています。こちらも、およそ想定していた通りの結果となりました。
これまでの検証結果から、scoreとmagnitudeの評価のされ方についてある程度分かってきました。実際にアンケートデータの分析で使用する場合は、今回のように様々なパターンのダミーデータを事前に分析することである程度scoreの取り得る値を調べておき、「score0.6以上なら5段階評価で5とする」などと基準を設定しておけば、文章だけのアンケートデータからでも、評価を数値化できそうだと感じました。
おわりに
感情分析の結果は想定通りであったものの、表示された数値には絶対的な基準がないため、自分で評価基準を決める必要があります。うまく使いこなすには経験が必要だと感じました。また、これまで感覚で掴んでいたものが数値として表れるのは、興味深い体験でした。
今回は短文のダミーデータを使用しましたが、長文のレビュー内容の分析もしてみたいと思います。みなさんもぜひ試してみてください!
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- OWASP
- SASE
- Tech Crawling
- XDR